시계열 데이터 특성
: Level + Trend + Seasonality + Noise (Error)
- Level은 Decomposition이 불가능해서 Noise에 속한다.
Trends
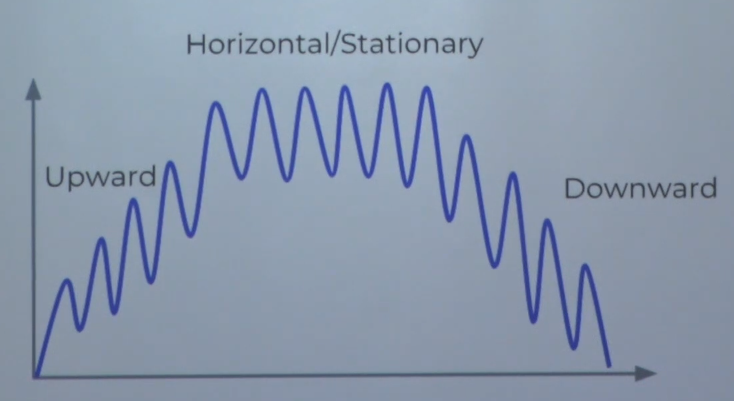
Seasonality
: 반복되는 트렌드

Cyclical
: 일정하지 않은 기간의 트렌드

+Noise
ETS모델
: 데이터의 패턴을 더 잘 파악하기 위해서 또는 예측을 수행하기 위해 Smoothing을 한다.
Smoothing을 위해서 Error, Trend, Seasonality 요소들을 활용하는데, 각각을 더하거나 곱하여 Smoothing을 한다.
이것들을 가지고 시계열 데이터를 모델링 할 수 있다.
ETS Decomposition
: ETS 컴포넌트들을 시각화 하는 것은 데이터의 흐름을 이해하는데 큰 도움이 된다.


데이터를 다뤄보자

statsmodels.tsa.seasonal 에서 seasonal_decompose를 import해오고
임의의 Linear데이터 를 만들어서 series로 저장했다.

seasonal_decompose를 사용해서 만들어낸 데이터 series를 decompose해보면
위와 같은 옵션들이 있다(observed, resid, seasonal, trend 등)
plot을 그려보면
그래프가 너무 작다.
함수를 하나 만들어서 subplots로 각각 설정해보자.

seasonal_decompose함수의 return object를 parameter로 받는 plot_decompose 함수를 만들고,
plt.subplots를 통해서 4 x 1 subplot을 만들면서 figsize = (15,8)로 그래프 크기를 좀 키워주자.
return 값으로 fig(전체) , 각각의 row에 대한 ax1 ~ ax 4까지 나오게 되고,
각각의 plot을 그리면 ax = ax1이런식으로 넣게 되면 각각의 그래프의 위치를 잡아 줄 수 있다.
잠깐 subplots를 알아보면
fig와 axes를 return하고, 각각은 그래프들의 위치를 지정할 수 있다.
아래를 보자
위 4 x 1그래프 집합들을 2x2로 바꾸고 싶다면

axes를 받고, axes[0][0] ~ axes[1][1]까지 2 x 2 행렬을 사용하는 것 처럼 위치를 지정해주면 된다.

이번엔 multiplicative 모델을 하나 만들어주고 에러는 귀찮아서 뺐다.

decomposition해준것을 그려주면 위와 같이 나온다.
airline 데이터 시각화

데이터를 가져와서 그리니 위와같은 그래프가 나오는데,

하나밖에 없는 Thousands of Passengers를 decompose해보고 그려보면

게시글 초반의 모습과 동일한 것을 볼 수 있다.
'Data Handling > 시계열데이터' 카테고리의 다른 글
| ARIMA 모델 (0) | 2021.01.04 |
|---|---|
| Pandas로 하는 시계열 데이터분석 (4) [시계열 데이터 분석 기본 모델] (0) | 2021.01.01 |
| Pandas로 하는 시계열 데이터분석 (2) [TimeZone, Visualize] (0) | 2020.12.29 |
| Pandas로 하는 시계열 데이터분석 (1) (0) | 2020.12.28 |