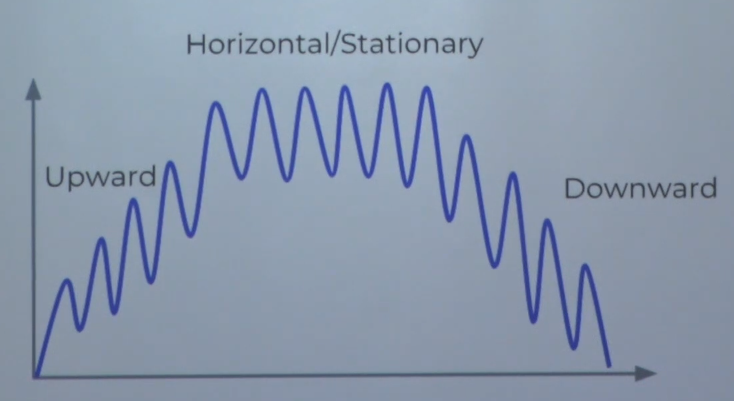
ARIMA 모델 Autoregressive Integrated Moving Average는 개발된지 오래된 방법이지만 시계열 데이터 분석을 위해 이해해야 하는 중요한 모델링 또는 예측 기법이다. 여기 나오는 개념들을 이해하는것이 좋다. Stationary vs Non-stationary time series Seasonal vs Non-seasonal ARIMA Autoregressive - AR(p) Integrated - I(d) Moving Average - MA(q) Stationary 데이터 특성 - 연속되는 숫자들의 평균 / 분산 / 공분산이 시간에 따라서 변하지 않으면 Stationary하다고 한다. ARIMA 모델이 효과적으로 적용이 되려면 Data가 Stationary 특성을 보여야한다...