6-1장 SELECT FROM



USE [DB name] : 어떤 DB에 접근할건지
SELECT * FROM [table name] : 테이블의 모든 column내용 조회
SELECT [columns] FROM [table name] : 테이블의 특정 column조회
- ex) SELECT first_name, gender FROM employees;
: 여러 열 조회
SHOW DATABASES; : DB목록 조회

SHOW TABLE STATUS; : 현재 선택된 DB의 테이블들의 정보 조회

DESCRIBE [table name]; : 해당 table의 정보 조회

6-2장 샘플 데이터베이스 생성


6-3장 WHERE절
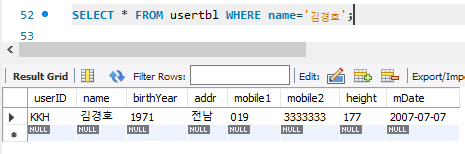
1.특정 column의 값 지정
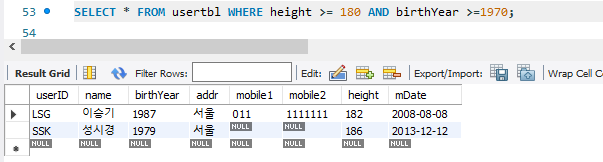
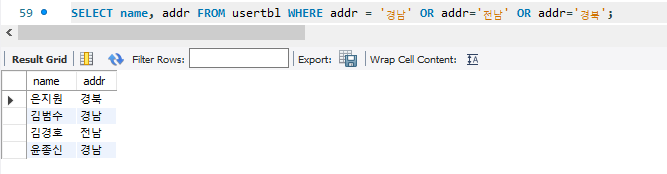
2. 관계연산자 사용 - AND, OR

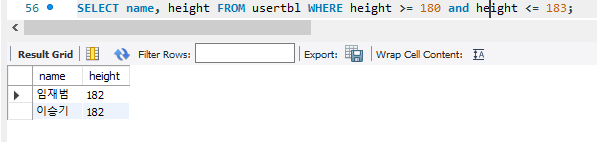
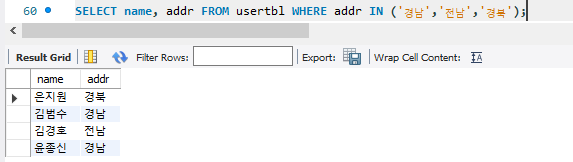
3. BETWEEN ... AND와 IN() 그리고 LIKE
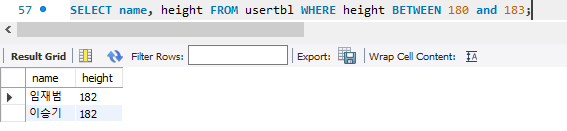
BETWEEN AND예시 180~ 183 사이의 키를 가지는 사람 검색하는 방법
WHERE ... IN 방식으로 조회예시
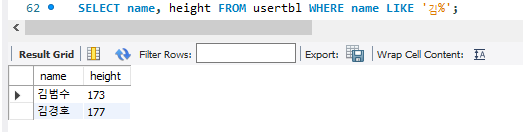
LIKE : 문자열 검색시 사용
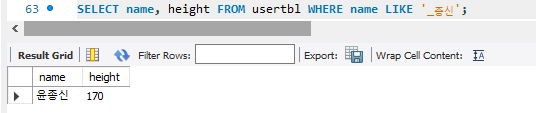
김씨 검색 예시 / 한글자만 비우고 찾는 방법
4. ANY/ALL/SOME 그리고 서브쿼리(SubQuery, 하위쿼리)
서브쿼리 : 쿼리문 안에 또 쿼리문이 들어있는 것
김경호보다 키가 큰 사람들의 정보를 출력하고 싶다면
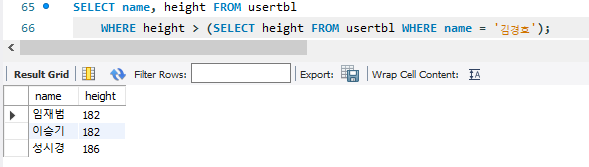
지역이 '경남'사람의 기보다 키가 큰 사람을 추출하고 싶은데 아래와 같이 작성하게 되면


이런 ERROR를 만난다. 왜냐하면 서브쿼리의 결과가 하나가 아니기 때문이다.
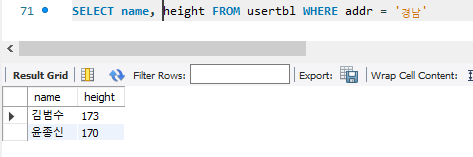
이를 해결하기 위해선 경남 사람의 키인 173, 170중 작은사람이 170이니, 170보다 크기만 하면 되게끔 선택하게 해줘야한다.
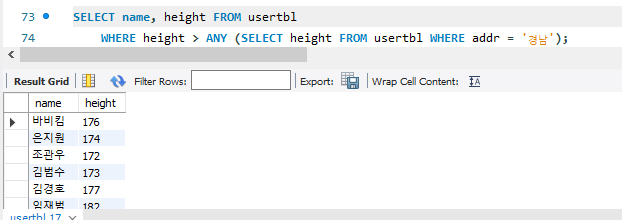
170, 173이 있는데, ANY를 쓰면 170이 선택되었다. 173이 선택되려면 어떻게 해야할까 ?
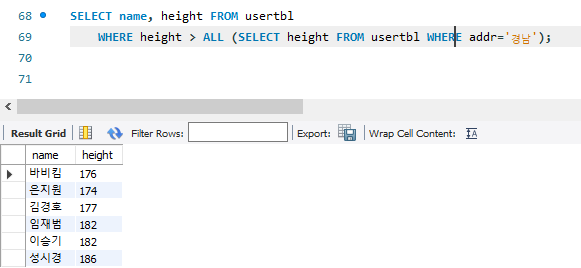
170, 173 둘다 만족하게 하는 ALL을 사용하면 된다.
5. ORDER BY : 원하는 순서대로 출력
기본적으로 오름차순이고, 끝에 DESC를 붙여주면 내림차순으로 할 수 있음.
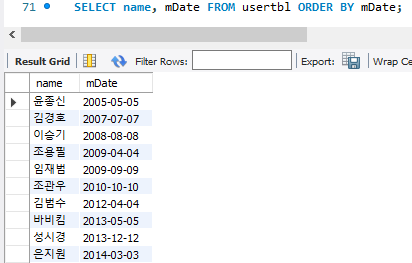
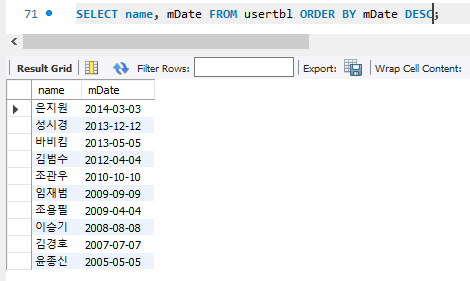
두가지 이상을 정렬하고 싶으면 어떻게 할까 ?
이승기와 임재범의 키가 같아서 이승기가 먼저 출력된 것을 볼 수 있다.
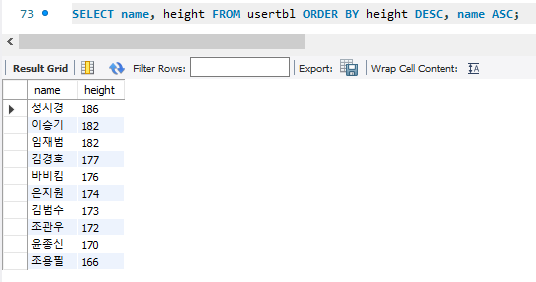
ORDER BY절은 MySQL성능을 다소 떨어뜨릴 수 있어서 되도록 사용하지 않는게 좋음.
6. DISTINCT : 중복제거
중복을 제거하고 보고 싶다면 어떻게 할까 ?
아래와같이 DISTINCT절을 사용해서 중복을 제거해보면 된다.
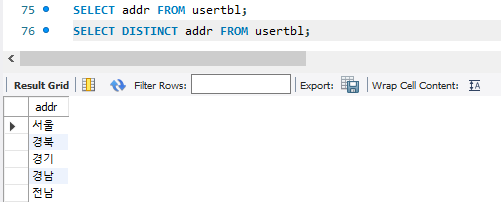
7. LIMIT N : 출력 개수 제한하기
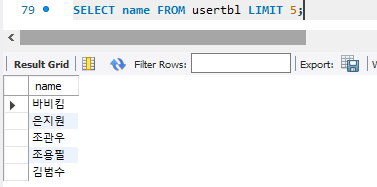
5로 사용하게되면 0~4까지 출력되고, 범위 지정도 가능하다.
LIMIT 5,10으로 하게되면 5번 인덱스부터 9번 인덱스까지 출력된다.
8. 테이블 복사하기

위와같이 쓰면 테이블을 복사할 수 있는데, 이 때 PK, FK는 복사되지 않는다.
6-4장 Group By, Having절
1.GROUP BY
순서는 지켜져야함.

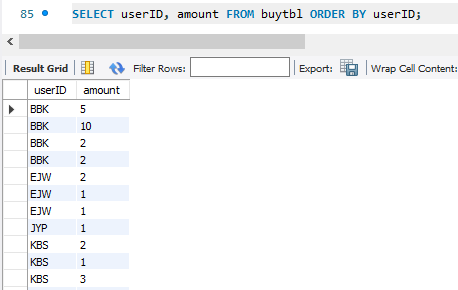
유저별로 물품을 몇개나 샀는지 구하기 위해 유저ID로 정렬해서 수작업을 한다 ?
말이 안되고, 이럴떄 userID로 묶어서 sum을 진행하면 된다.
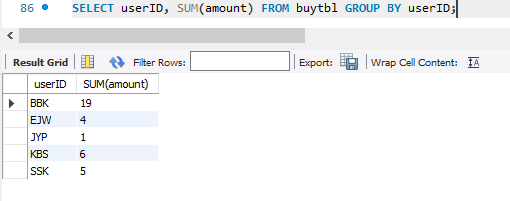
AS를 사용하면 출력시 column명을 바꿀 수 있다.
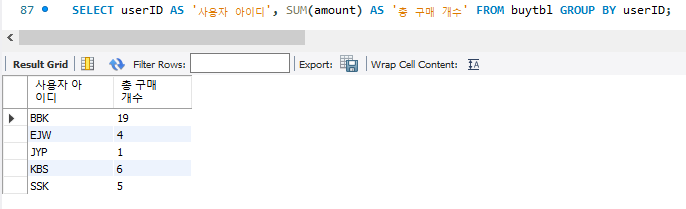
얼마나 지출했는지, 구하자면 아래와같은 연산이 가능하다.
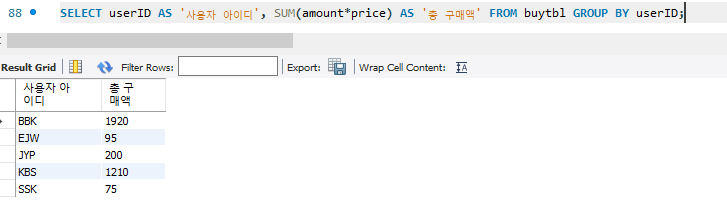
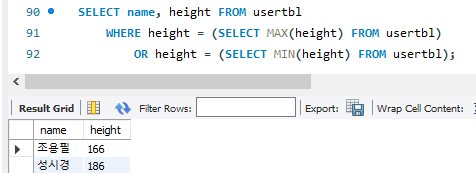
키가 가장 큰사람과 가장 작은 사람을 조회하려면 어떻게 해야할까
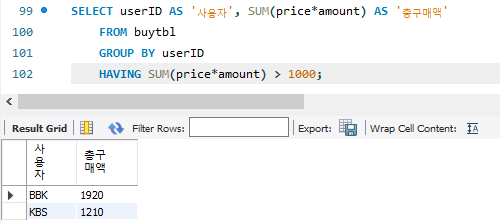
구매액이 1000이상인 사람들 추출하려면 어떻게 해야할까?
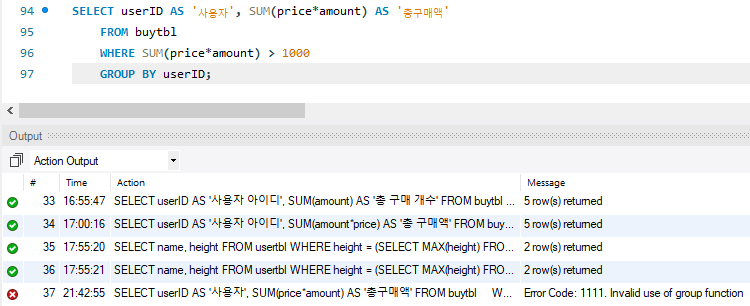
GROUP BY를 썼는데 WHERE을 쓰게되면 37번 라인과 같은 오류가 나타난다.
GROUP BY를 썼을떈 HAVING절을 사용해줘야한다.
2. HAVING : GROUP BY 에 대한 결과에 조건을 걸어야할 때.
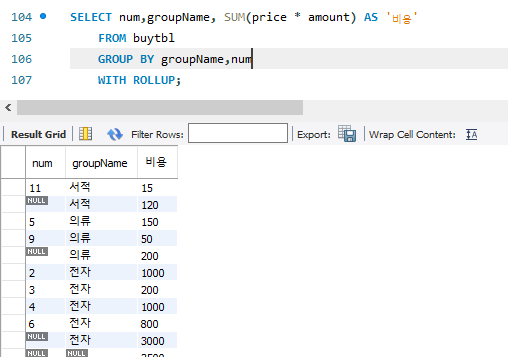
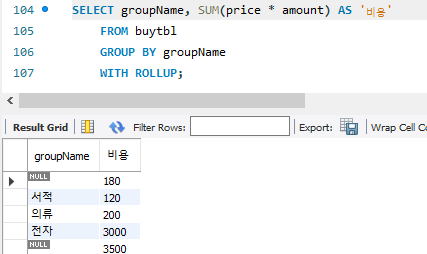
3. ROLLUP : 총합 또는 중간 합계가 필요하면 GROUP BY와 함꼐 WITH ROLLUP문을 사용하면 됨
4. SQL문의 분류(DML, DDL, DCL)
** Transaction (트랜잭션)이란 ? : 테이블의 데이터를 변경(입력/수정/삭제)할 때, 실제 테이블에 완전히 적용하지 않고, 임시로 적용시키는 것을 말함. 만약 실수했다면 임시로 적용했기에 적용을 취소시킬 수 있음.
1. DML (Data Manipulation Language)
: SELECT, INSERT, UPDATE, DELETE
: 트랜잭션이 발생함.
2. DDL (Data Definition Language)
: CREATE, DROP, ALTER 등
: 트랜잭션을 발생시키지 않음. 그래서 되돌리거나 완전적용이 아니라 즉시 MySQL에 적용됨
3. DCL(Data Control Language)
: GRANT, REVOKE, DENY 등
6-5장 INSERT, UPDATE, DELETE절
1. INSERT : 테이블에 데이터를 삽입하는 명령어
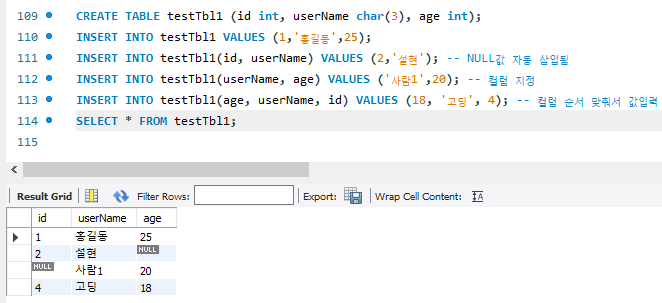
2. AUTO_INCREMENT : id값이 자동으로 올라가게끔, 보통 PRIMARY KEY지정.
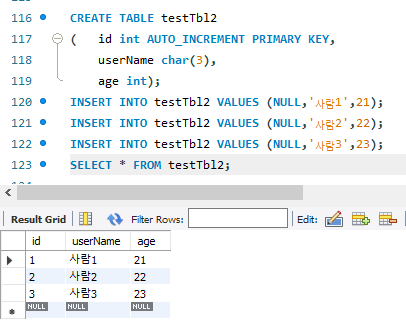
현재 ID가 몇까지 증가되었는지 확인하려면 LAST_INSERT_ID()를 조회하자.
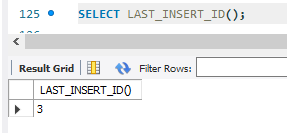
ID값을 100부터 입력되도록 변경하고 싶다면 다음과 같이 수행함
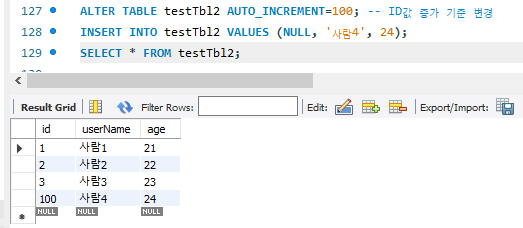
증가값을 1씩이 아니라 다르게 증가시키려면 어떻게 해야할까 ?
서버의 증가값을 변경해주어야한다.

다른 테이블에서 가져와서 새 테이블을 만들려면 어떻게 해야할까 ?
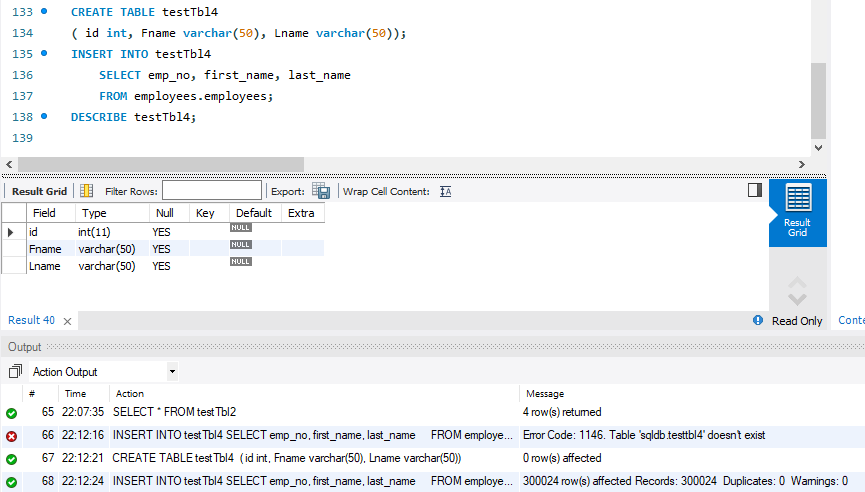
30만건이 추가된 것을 볼 수 있다.
3. UPDATE : 데이터의 수정 (기존 값을 변경하기 위해서 사용)

WHERE절은 생략이 가능하지만, WHERE을 생략하면 테이블의 전체행이 변경되니 유의하자.
Fname이 Kyoichi를 가지는 인원들의 Lname을 바꾸려면
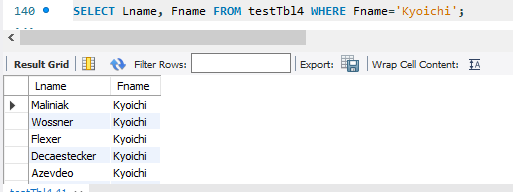
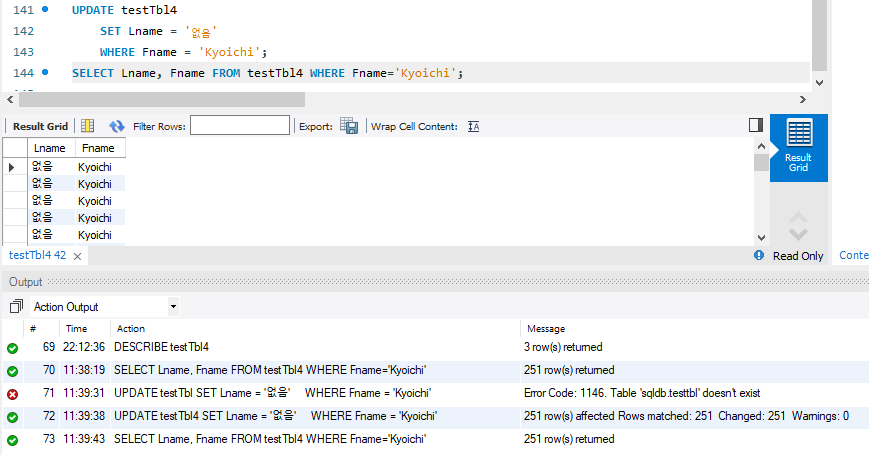
251개의 행이 모두 바뀐 것을 확인 할 수 있다.
WHERE절이 없으면 30만건이 모두 바뀌니 조심하자.
4. DELETE FROM : 데이터 삭제 ( 행 삭제 )

대용량 데이터를 만들고, 삭제해보자.
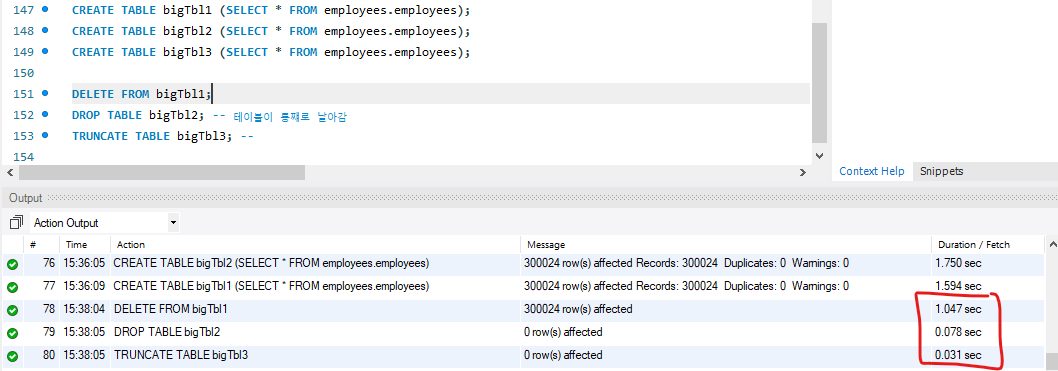
DELETE : 1.047초 ( 한 행씩 삭제 )
DROP : 0.078초 ( 테이블 통째로 삭제 )
TRUNCATE : 0.031초 ( 테이블 통째로 삭제 )
DELETE, TRUNCATE은 테이블 구조는 유지되나, DROP은 테이블 자체가 삭제됨.
5. IGNORE : 조건부 데이터입력, 변경
PK가 중복된 데이터를 입력해서 100건 중에 첫건에서 오류가 난다면 나머지도 입력이 되지 않는 오류가 발생한다.
오류가 발생해도 진행하는 방법을 제공함.
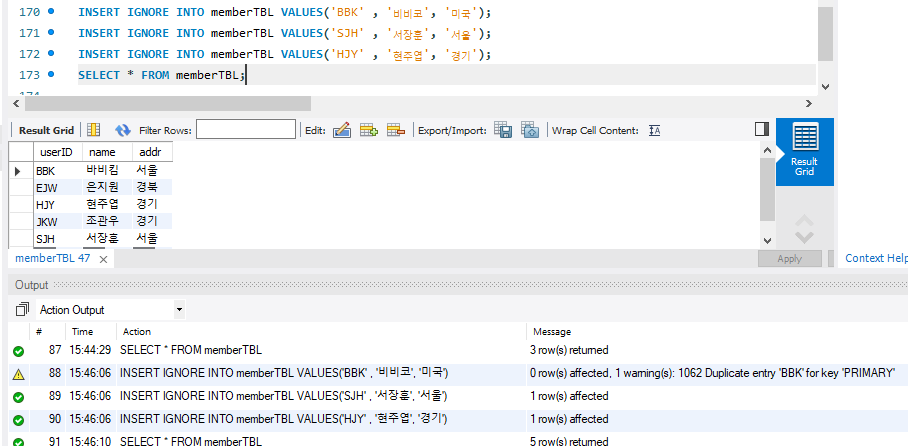
3건을 가져오고 userID를 PK로 지정해 둔 상태에서 BBK가 중첩되게 들어가면 아래와같이 오류가 뜬다.
오류가 발생하면 166,167의 INSERT문도 적용되지 않는다.
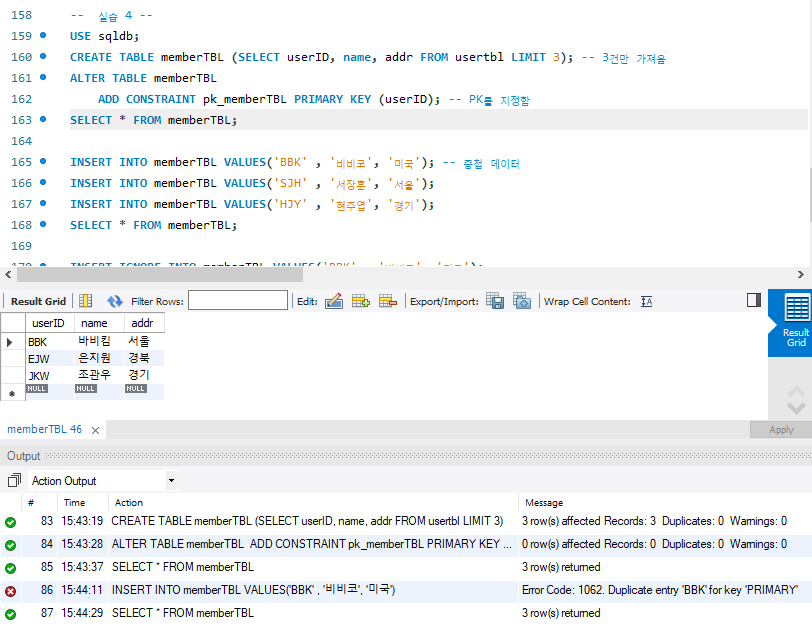
IGNORE을 사용하면 오류가 나더라도 이후 쿼리를 진행하게 된다.
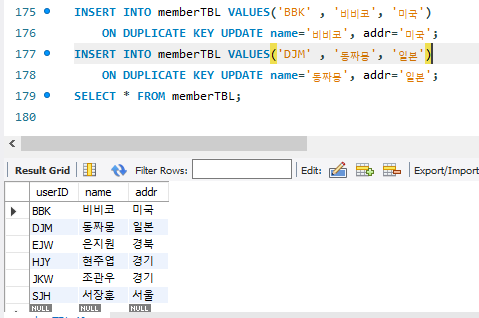
키가 중복되면 업데이트 되게끔 할 수도 있음.
6. WITH절과 CTE 간단하게
CTE는 비 재귀적, 재귀적 방식이 있음.
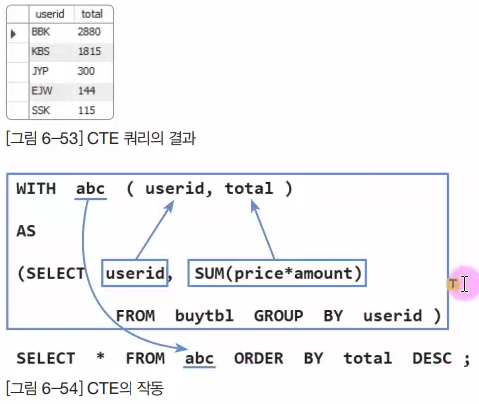
그러니까 테이블을 하나 새로 만든 것 취급해서 abc라는 테이블이 만들어지고 이를 사용 할 수 있게됨.
'Data Handling > MySQL' 카테고리의 다른 글
| 7장 SQL 고급(1장 , 2장) (0) | 2022.02.23 |
|---|---|
| 3장 - 4,5교시 정리 (0) | 2021.06.12 |
| 03장- 1/2/3 교시 내용 정리 (0) | 2021.06.01 |