
모델이 없는 상황에서 정책 추정하는 방법 2가지
몬테 카를로 : 어떤 함수의 평균값을 샘플을 통해서 추산할 수 있다.
-> 가치함수 추정하는데 사용했음(샘플을 통해서 추정했음)
DP와 MC 기법의 장단점

Temporal -difference는 둘을 섞은 알고리즘
Q-learning의 기초가 되는 알고리즘.

Gt를 직접적으로 샘플을 통해서 얻어진 보상들을 감가하고 합하여 리턴의 추산치로 사용했음

TD에서는 return을 추산할 때 현재상태의 보상인 Rt+1과 감마만큼 감소한 다음상태의 가치함수를 사용하게 된다.
MDP를 십분 활용한 것.
MC기법 현재의 보상 ~ terminal
MDP라고 가정하면 현재 이후는 V(St+1)로 대체 된다.
V(s) 를 조정해서 TD target과 가까워 지게 만드는게 목적.
TD error 현재 추산이 얼마나 틀렸는가 .
DP에서 벨만에러가 높은 순서대로 State를 업데이트하는 알고리즘이 존재했었음. (좀 더 빠르게 수렴)
TD에서도 TD error가 높은 순서대로 State 업데이트 하는 알고리즘이 존재함.
Monte Carlo와 Temperal difference 비교

MC는 기본적으로 에피소드가 끝나야 적용가능.
TD는 에피소드가 끝나지 않아도 적용가능. 현재상태의 보상과 다음상태 가치함수의 추산치만 있으면 되기 때문이다.
MC 기법은 불편(향) 추정치였기 때문에 데이터가 충분히 많다면 참값을 추산할 거라고 기대할 수 있다.
MC 기법은 높은 분산을 가지기 때문에 분산에 유의해야한다.
TD기법은 반대인데 Return 추산에 변동성을 줄 수 있는 것은 현재상태에서의 보상뿐이다. 따라서 MC기법에 비해서 분산이 낮다.
MC기법의 경우엔 현재부터 종결상태까지 모든 분산들이 매 시행, 에피소드마다 달라지는 확률변수였기떄문에 분산이 커지는 것.
TD target을 업데이트 하는 방식은 분산을 줄이는 대가로써 불편추정치의 특성을 포기해야만 했다.
MDP의 구조를 얼마나 활용하는가.
MC는 활용하지 않지만 TD는 활용한다. (꽤나 중요한 얘기인것 같은데 제대로 이해 못한듯.. .ㅠ)
'큰 문제'에서 Full-width backup

DP는 가능한 모든 S, A에 대해서 동기적으로 업데이트하는 과정을 거쳤고, 매우큰 S,A 공간에 대해서는 계산량이 매우 많아지게 된다. 비동기적 DP 도 배웠다.
MC, TD기법은 비동기 DP의 학습버전으로 생각하면 된다.
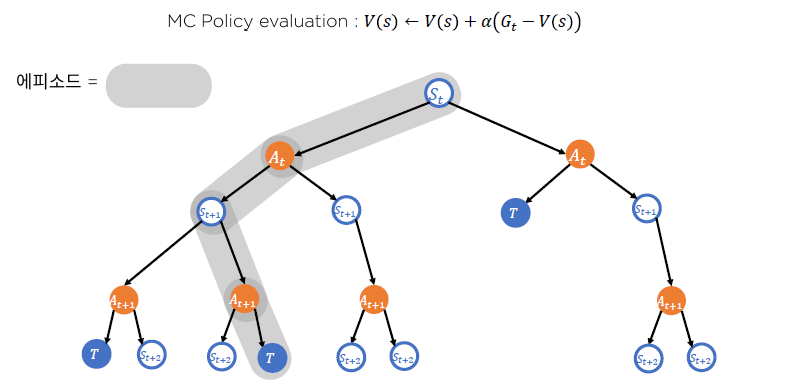
MC는 terminal State가 나올 때 까지 학습.
전체 S,A가 얼마나 크든 저장만 할 수 있다면 MC기법을 활용해 학습하는 것이 가능함.

TD는 현재 state+ 다음state의 가치함수까지만 보면 되기 때문에 MC보다 메모리 효율적
결국 둘간의 차이는 한번 가치함수 업데이트에 필요한 깊이차이. 몇step뒤의 상태를 참고하느냐.
여러 스탭의 보상을 활용한 TD: n-step TD

무한스탭 : 몬테카를로와 동일해진다.
Gt(n) = n스탭 뒤의 정보까지 활용한 return. n 이후는 우리가 알고있는 V로 대체하겠다.
그럼 n을 얼마나 크게 해야, 작게해야 하는가 ?
너무 크면 분산문제가 있고, 작게 하면 편향문제가 있다.
서로 다른 추정치를 모두 사용하여 하나의 Gt 추정치를 만들수는 없을까?
여러개의 추정치를 하나의 추정치로 표현하기

dumb -> 최소 T배 : 너무 커짐. scaling해줄게 필요함.
TD(λ)

람다를 0~ 1사이로 조절함
0에 가까워질 수록 분산을 최대로 낮춰볼 수 있고 1에 가까워지면 분산을 늘리는 대신에 편향을 줄일 수 있게된다.

바로 직후상태에서 얻는 보상과 자신의 가치 추정치를 동시에 활용해서 리턴을 추정하는 것.
그 추정된 리턴을 가지고 가치함수를 추정하는 방법
TD를 확장해서 여러스탭의 보상을 활용하는 n-step TD.
여러 스탭을 하나로 합치는방법인 TD(람다)
TD람다보다는 n-step에서 n을 찾는 형태로 많이들 사용한다.
'인공지능 > Reinforce_Learning' 카테고리의 다른 글
| [PART2] CH04. SARSA TD 기법을 활용한 최적정책 찾기 (0) | 2020.12.22 |
|---|---|
| [PART2] CH04. Monte Carlo 기법을 활용한 최적 정책 찾기 (0) | 2020.12.22 |
| [PART 2] Ch3. 몬테카를로 (0) | 2020.11.24 |
| [Part2] 동적계획법 - 비동기적 동적계획법 (0) | 2020.11.20 |
| [Part2] ch.2 동적 계획법(Dynamic programming) (0) | 2020.11.19 |