반응형
TD 복습

TD(n) : n-step까지의 Return + 이후의 가치 추산치 활용
SARSA : TD(0)를 활용한 행동 가치 함수 Q파이 추산
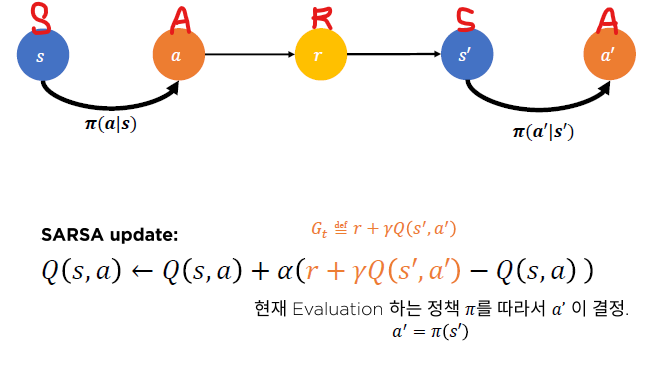
SARSA 의사 코드

임의의 policy에 대해서 가치를 추산하는 코드...
sampling된 에피소드에 대해서 terminal state가 될때까지 반복한다.
SARSA control : SARSA policy evaluation + e-탐욕적 정책 개선

GLIE조건을 만족시키면서 학습시키는건 어렵다.
현실적으로 좋은 성능을 보이지도 않음.
n-step TD복습

n-step SARSA

SARSA(람다)
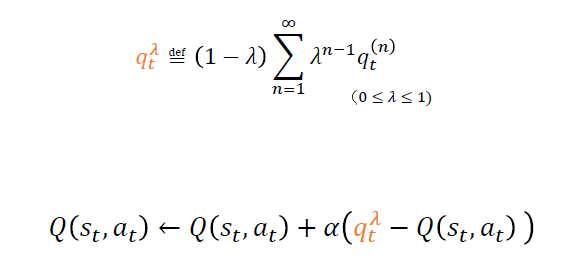
람다는 파라미터고 람다가 1에 가까워질수록 분산이 커지고 편향이 낮아지고
람다가 0에 가까워질수록 분산이 작아지고 편향이 커진다.
반응형
'인공지능 > Reinforce_Learning' 카테고리의 다른 글
| [Part2] CH05. Off-policy TD contorl과 Q-Learning (0) | 2020.12.23 |
|---|---|
| [PART2] CH05. Off-policy MC control (0) | 2020.12.23 |
| [PART2] CH04. Monte Carlo 기법을 활용한 최적 정책 찾기 (0) | 2020.12.22 |
| [PART2] CH03. Temporal Difference (TD) 정책추정. (0) | 2020.12.21 |
| [PART 2] Ch3. 몬테카를로 (0) | 2020.11.24 |